
Milano e Palermo: le mappe della distribuzione della popolazione straniera residente nel 2018
 1-2 giugno si svolgerà a Milano il raduno di Spaghetti Open Data del 2019 (in breve SOD19) presso la Fabbrica del Vapore, il programma e le proposte per l’hackathon del raduno si discutono nella Mailing-list di Spaghetti Open Data, tra tutte le proposte la mia attenzione è stata attirata dal post di Alberto Cottica, ovvero provare a fare una versione milanese della visualizzazione di Bruxelles Melting Pot.
1-2 giugno si svolgerà a Milano il raduno di Spaghetti Open Data del 2019 (in breve SOD19) presso la Fabbrica del Vapore, il programma e le proposte per l’hackathon del raduno si discutono nella Mailing-list di Spaghetti Open Data, tra tutte le proposte la mia attenzione è stata attirata dal post di Alberto Cottica, ovvero provare a fare una versione milanese della visualizzazione di Bruxelles Melting Pot.
In breve, è una mappa one person one dot dove ogni pixel rappresenta un abitante non nato in Italia. Il colore del pixel rappresenta la nazionalità: europea, nord-africana, asiatica etc. La mappa serve a capire se c’è segregazione spaziale. A Bruxelles c’è, con gli europei che abitano più a sud e est, i nord africani a nord e ovest, i turchi a nordest etc. (cit) L’idea mi affascina e visto che non potrò andare al raduno, penso… Se sul portale open data del Comune di Palermo ci sono i dati statistici sulla popolazione residente al 2018, perché non farne anche una versione palermitana…e dare il mio piccolo contributo al raduno ?
L’idea mi affascina e visto che non potrò andare al raduno, penso… Se sul portale open data del Comune di Palermo ci sono i dati statistici sulla popolazione residente al 2018, perché non farne anche una versione palermitana…e dare il mio piccolo contributo al raduno ?
Per realizzare una buona mappa occorre un dataset come quello pubblicato dal Comune di Milano, con i dati anagrafici della popolazione residente distinta per anno, età, sesso, cittadinanza e quartiere, cosa che non sono riuscito a trovare per Palermo.
Sulla popolazione residente straniera ho trovato solo una pubblicazione in pdf GLI STRANIERI A PALERMO NEL 2018 sul sito tematico Pubblicazioni Statistiche.
Sfogliando la pubblicazione pdf, a pagina 21 noto una tabella, Tavola 6: Cittadini al 31/12/2018 per cittadinanza a circoscrizione; non era esattamente quello che cercavo, ma pazienza, con un po di lavoro in più si possono tirar fuori i dati anche pdf 🙂
Come replicare la mappa di Bruxelles Melting Pot
Studiando gli esempi suggeriti da Alberto Cottica, (Mailing-list di Spaghetti Open Data) Bruxelles Melting Pot e One-person-one-dot maps and how to make them replicare la mappa non è impossibile.
Gli ingredienti di base sono:
- Dataset ben strutturato di dati statistici;
- Dataset dei poligoni del territorio da analizzare;
- Semplici conoscenze del software QGIS o altri software GIS
Visto che il Comune di Milano rende disponibile in opendata entrambi i dataset, ho preferito iniziare da Milano l’analisi della popolazione residente; capito il metodo, lo si può replicare in tanti altri casi.
Grazie a Tommaso Dardi per aver indicato dove trovare i dataset di Milano – Popolazione: residenti per cittadinanza e quartiere, Territorio: localizzazione dei quartieri della città (Nuclei d’Identità Locale – NIL)
Il dataset sulla popolazione residente di Milano è un ricchissimo file con le serie storiche dal 1999 a 2018: contiene 2.136.906 di righe, indigeste ai normali fogli di calcolo, proprio per questo motivo sul portale è consigliato l’uso di pacchetti statistici o software per la gestione di database (DataBase Management System), in quanto i file possono superare il numero massimo di record supportato dai normali fogli elettronici. Per il mio test ero interessato soltanto ai dati relativi all’anno 2018. Per estrarli ho usato QGIS, ma si può fare in altri modi, come importando il file in data.world ed eseguendo una query per anno, oppure utilizzando VisiData come il maestro @aborruso.
Per il mio test ero interessato soltanto ai dati relativi all’anno 2018. Per estrarli ho usato QGIS, ma si può fare in altri modi, come importando il file in data.world ed eseguendo una query per anno, oppure utilizzando VisiData come il maestro @aborruso. Con una semplicissima selezione “Anno” = ‘2018’ otteniamo i dati di nostro interesse.
Con una semplicissima selezione “Anno” = ‘2018’ otteniamo i dati di nostro interesse. Non ci resta che salvare la selezione, adesso con 131.162 elementi è più semplice lavorare.
Non ci resta che salvare la selezione, adesso con 131.162 elementi è più semplice lavorare.
Esempio di estrazione dei dati dell’anno 2018 con data.world e query Con data.world è sufficiente importare il file .csv scaricato dal portale opendata del Comune di Milano Popolazione: residenti per cittadinanza e quartiere e scrivere una nuova query:
Con data.world è sufficiente importare il file .csv scaricato dal portale opendata del Comune di Milano Popolazione: residenti per cittadinanza e quartiere e scrivere una nuova query:
select * from ds27_pop_sto_quartiere where ds27_pop_sto_quartiere.anno like "2018"cliccare su Run query e dopo qualche secondo di attesa otteniamo i dati relativi all’anno 2018.
Estratti i dati del 2018 possiamo iniziare a giocare 🙂
Come strutturare i dati
Il nostro obbiettivo è quello mappare i residenti di ogni quartiere, aggregati per Paese, Continente o Sub-Regione di provenienza. Come prima cosa dobbiamo conoscere il numero totale dei residenti aggregati per Paese, Continente e Sub-Regione di provenienza.
L’aggregazione, può essere fatta velocemente con le Tabelle-Pivot (grazie Andrea Borruso), per comodità ho usato Google sheets, la stessa procedura può essere fatta con Libreoffice ed Excel e con QGIS usando il plugin Group Stats (grazie a Salvatore Fiandaca per le info QGIS).
Ad un primo confronto con i dati di Bruxelles mi rendo conto che nei dati di Milano mancano le informazioni sul Continente e la Sub-Regione di provenienza, per cui è necessario aggiungere due colonne ed aggiungere le relative informazioni. Con l’aiuto di wikipedia.org ho trovato le Sub-Regioni:
Con l’aiuto di wikipedia.org ho trovato le Sub-Regioni:
- Central Asia
- East Asia
- South Asia
- Southeast Asia
- Western Asia
- North Africa
- Sub-Saharan Africa
- North America
- South America
- Oceania
Dal sito Eurostat Statistics Explained:
- EU-N13
- EU-15
- EU-28
- Europeans out of EU
Aggiunte le nuove info, possiamo costruire tutte le tabelle-pivot necessarie per la nostra analisi. La tabella in alto rappresenta l’aggregazione della popolazione residente per quartiere e sub-regione di provenienza, visto che vogliamo fare anche un confronto residenti stranieri e italiani, quest’ultimi non sono stati inseriti nella sub-regione, (EU-15).
La tabella in alto rappresenta l’aggregazione della popolazione residente per quartiere e sub-regione di provenienza, visto che vogliamo fare anche un confronto residenti stranieri e italiani, quest’ultimi non sono stati inseriti nella sub-regione, (EU-15).
Mappa One-person-one-dot
Come realizzare la mappa a densità di punti una persona un punto…? Ecco un interessante post One-person-one-dot maps and how to make them che ci spiega cosa sono le mappe a densità di punti e come realizzarla QGIS.
In sintesi, sono necessari due file: uno del territorio che si vuol mappare e i dati statitici che vogliamo rappresentare di quel territorio.
Carichiamo i file in QGIS, per comodità mi sono creato un Geopackage, dove ho caricato i file necessari al test.  Eseguiamo una Join tra i poligoni (nilzome) e le tabelle che abbiamo estratto in precedenza, usando come campo unione ID_NIL, selezioniamo solo le colonne utili e lasciamo vuoto il campo del prefisso da utilizzare per le nuove colonne.
Eseguiamo una Join tra i poligoni (nilzome) e le tabelle che abbiamo estratto in precedenza, usando come campo unione ID_NIL, selezioniamo solo le colonne utili e lasciamo vuoto il campo del prefisso da utilizzare per le nuove colonne. Ecco la nuova tabella, con il totale dei residenti vari quartieri, aggregati per sub-regioni.
Ecco la nuova tabella, con il totale dei residenti vari quartieri, aggregati per sub-regioni.
Adesso non ci rimane che creare un nuovo layer di punti casuali, utilizzando i poligoni dei quartieri, uno per ogni subregione. Aprire il pannello Strumenti Processing, dal menù ‘Processing’ –> ‘Strumenti’, scrivere nel cerca il nome del comando da eseguire, ‘Punti casuali dentro poligoni’, in inglese ‘Random points in polygons’ e:
Aprire il pannello Strumenti Processing, dal menù ‘Processing’ –> ‘Strumenti’, scrivere nel cerca il nome del comando da eseguire, ‘Punti casuali dentro poligoni’, in inglese ‘Random points in polygons’ e:
- Selezionare il vettore d’ingresso, potrebbero esserci più layer di poligoni;
- selezionare il campo/espressione che si desidera mappare
- Dare un nome al file e specificare il percorso di salvataggio, se lasciato vuoto verrà creato un file temporaneo;
cliccare su esegui, nel giro di pochi secondi il nuovo layer sarà generato. Se dobbiamo ottenere ‘N’ layer, uno per ogni sub-regione possiamo eseguire un processo in serie.
Se dobbiamo ottenere ‘N’ layer, uno per ogni sub-regione possiamo eseguire un processo in serie. Prima di selezionare la colonna dati da mappare, clicchiamo su ‘Esegui come processo in serie‘ e configuriamo i parametri nella nuova finestra.
Prima di selezionare la colonna dati da mappare, clicchiamo su ‘Esegui come processo in serie‘ e configuriamo i parametri nella nuova finestra. Questa volta il processo sarà più lungo e dobbiamo attendere qualche minuto. Andrea Borruso e Salvatore Fiandaca sono a lavoro per uno script #arigadicomando, che velocizzi e automatizzi tutto il processo.
Questa volta il processo sarà più lungo e dobbiamo attendere qualche minuto. Andrea Borruso e Salvatore Fiandaca sono a lavoro per uno script #arigadicomando, che velocizzi e automatizzi tutto il processo.  La mappa inizia a prendere vita, diminuendo la dimensione dei punti la mappa sarà più leggibile.
La mappa inizia a prendere vita, diminuendo la dimensione dei punti la mappa sarà più leggibile. Per fare un confronto con mappa di Bruxelles Melting Pot non ci resta che adottare gli stessi colori.
Per fare un confronto con mappa di Bruxelles Melting Pot non ci resta che adottare gli stessi colori.











Ecco le mappe a densità di punti della popolazione residente di Milano 🙂
Qui il dataset costruito con tutte le tabelle-pivot ricavate dal google-sheets e rielaborato con Andrea Borruso e Salvatore Fiandaca, usato per il test, della popolazione residente a Milano nel 2018; il dataset contiene i dati anagrafici della popolazione residente distinta per età, sesso, cittadinanza e quartiere e il geojson dei quartieri di Milano (Nil – Nuclei d’Identità Locale), per poter replicare il test e miglioralo, e per realizzare altri elaborati. Licenza CC0
 Grafico realizzato con Tableau Public che mette a confronto la popolazione residente, italiani e stranieri nei quartieri, aggregati per genere.
Grafico realizzato con Tableau Public che mette a confronto la popolazione residente, italiani e stranieri nei quartieri, aggregati per genere.
Il caso Palermo
Capito il metodo, torno a lavorare sulla mappa di Palermo, sicuro di dover faticare un pò di più 🙂
Come già detto i dati di base non sono ideali, li devo ricavare da una tabella in un file pdf, GLI STRANIERI A PALERMO NEL 2018, pagina 21, Tavola 6: Cittadini al 31/12/2018 per cittadinanza a circoscrizione.
 A questo punto la domanda mi sorge spontanea… chiudo tutto e vado a fare una passeggiata a Mondello o mi armo di pazienza e vado avanti…?
A questo punto la domanda mi sorge spontanea… chiudo tutto e vado a fare una passeggiata a Mondello o mi armo di pazienza e vado avanti…?
Dopo qualche minuto di perplessità ha prevalso l’amore per Palermo…si va avanti 🙂
La prima cosa da fare e convertire la taballa pdf human learning in una tabella machine learning, fortunatamente è un file pdf a è posso copiare direttamente la tabella nello sheet.  Prossimo passo organizzare un dataset simile a quello di Milano e Bruxelles per poter replicare l’esperienza.
Prossimo passo organizzare un dataset simile a quello di Milano e Bruxelles per poter replicare l’esperienza. Contestualmente alla riorganizzazione dei dati, aggiungiamo le colonne, Continents e Subregions, perché a me interessa l’aggregazione per Sub-Regione. Con i dati in possesso non è stato possibile suddividere i cittadini Europei in EU-N13, EU-15, EU28 e Europeans out of EU.
Contestualmente alla riorganizzazione dei dati, aggiungiamo le colonne, Continents e Subregions, perché a me interessa l’aggregazione per Sub-Regione. Con i dati in possesso non è stato possibile suddividere i cittadini Europei in EU-N13, EU-15, EU28 e Europeans out of EU.  Sempre con Tabella-Pivot ho estratto i dati della popolazione residente a Palermo nel 2018, aggregata per Circoscrizione e Sub-Regione di provenienza.
Sempre con Tabella-Pivot ho estratto i dati della popolazione residente a Palermo nel 2018, aggregata per Circoscrizione e Sub-Regione di provenienza.
Per replicare la mappa è necessario il file con i poligoni del territorio, in questo caso i le aree delle circoscrizioni sono state estratte dal dataset ISTAT Basi territoriali e variabili censuarie – Censimento 2011.
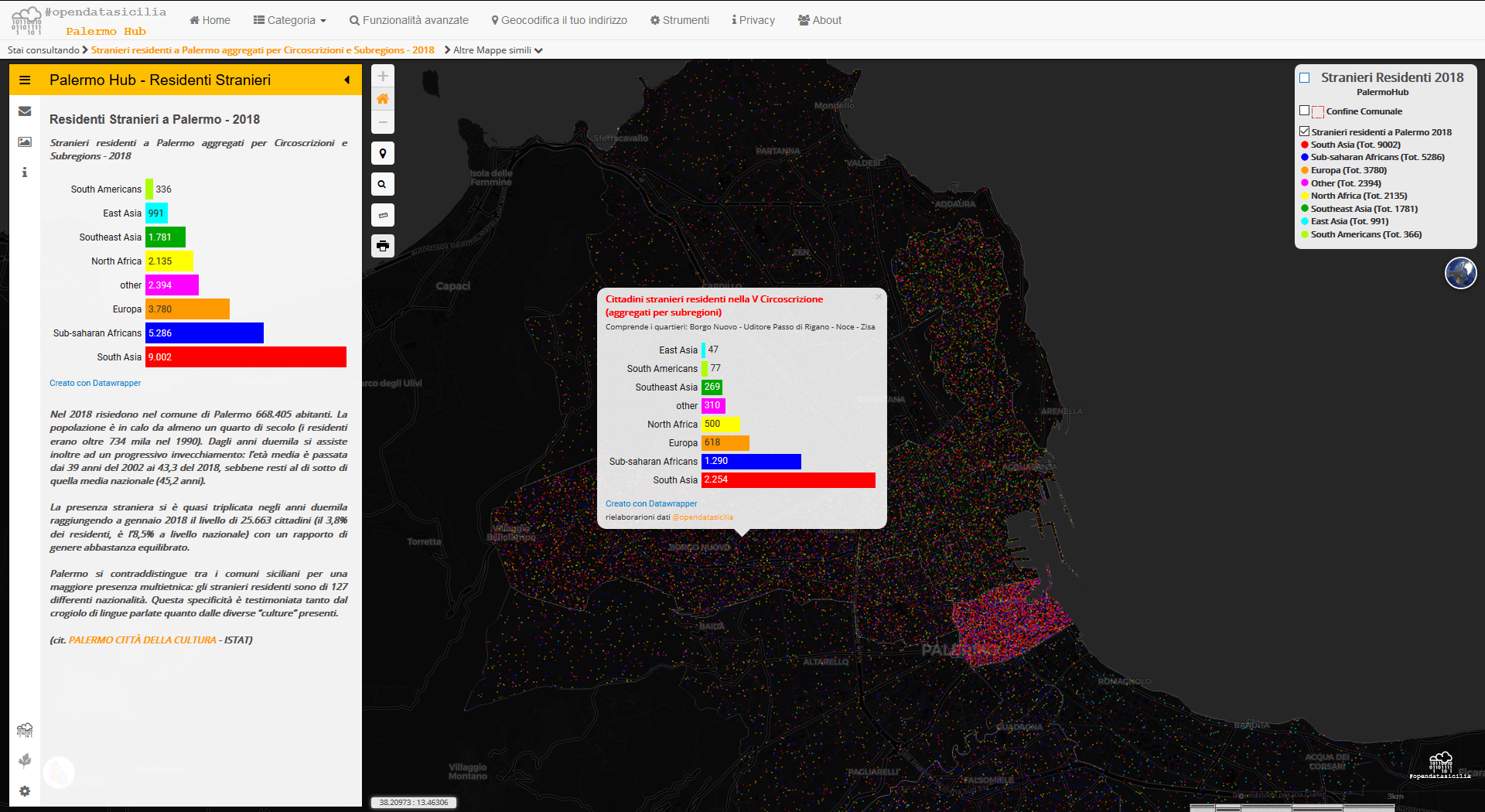
Mappa One-person-one-dot – Palermo
La procedura per ottenere i layer puntuali con QGIS è la stessa vista in precedenza, è cambiata la finalità, oltre alle immagini statiche, desidero ottenere una webmap, utilizzando QGIS e Leaflet Dopo aver ottenuto i singoli file di punti per ogni Sub-Regione ho usato la funzione ‘Merge‘ Fondi vettori, per ottenere un solo file di punti, più semplice da tematizzare.
Dopo aver ottenuto i singoli file di punti per ogni Sub-Regione ho usato la funzione ‘Merge‘ Fondi vettori, per ottenere un solo file di punti, più semplice da tematizzare. Caricato e tematizzato il nuovo layer, tutto è pronto per realizzare la webmap. Con il plugin QTiles vengono create le piastrelle ‘Tiles‘ del layer di punti, con il plugin qgis2web, viene creato tutto il pacchetto base delle webmab, usando il layer delle Circoscrizioni. Con Dreamweaver o con qualsiasi altro software che lavori con file html, si assemblano tutte le parti.
Caricato e tematizzato il nuovo layer, tutto è pronto per realizzare la webmap. Con il plugin QTiles vengono create le piastrelle ‘Tiles‘ del layer di punti, con il plugin qgis2web, viene creato tutto il pacchetto base delle webmab, usando il layer delle Circoscrizioni. Con Dreamweaver o con qualsiasi altro software che lavori con file html, si assemblano tutte le parti.
palermohub.opendatasicilia.it/stranieri_residenti_suregions
Per il grafico all’interno del tooltip è stata usata la webapp datawrapper (grazie Andrea Borruso) Sempre nella mappa non manca un Viz realizzato con Tableau Public e con i pochi dati disponibili.
Sempre nella mappa non manca un Viz realizzato con Tableau Public e con i pochi dati disponibili.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Qui il dataset costruito con tutte le tabelle-pivot ricavate dal google-sheets e rielaborato con Andrea Borruso e Salvatore Fiandaca, usato per il test, della popolazione residente a Palermo nel 2018, disponibile su data.world.
L’insufficienza dei dati disponibili, per quartieri o zone censuarie, rende la mappa a densità di punti per popolazione la straniera residente a Palermo, è un mero esercizio di stile, non paragonabile alle mappe di Milano e Brussels. Se in futuro ci saranno dati più dettagliati si potrebbe rieseguire l’analisi.
Riferimenti:
Brussels. A lovely Melting-Pot.
One-person-one-dot maps and how to make them
QGIS
Datawrapper
Tableau Public
Ringraziamenti:
- Andrea Borruso
- Salvatore Fiandaca
- Alberto Cottica (per aver proposto l’idea della mappa)