
OpenARS: una prima esplorazione dei dati
A meno di un mese da Open Data Sicilia 2018, che si terrà a Palermo il 9 e 10 novembre, entriamo adesso più nel vivo nel progetto OpenARS, i linked data dell’Assemblea Regionale Siciliana (ARS), che verrà presentato nel corso dell’evento.
Nell’ultimo post ci eravamo lasciati con la presentazione dell’ontologia OpenARS, creata per descrivere in modo formale le diverse tipologie di dati dell’ARS e le loro interconnessioni.
L’ontologia sviluppata consente di dare ad ogni risorsa un significato e di trasformare i dati dell’ARS in un enorme grafo direttamente interrogabile, esplorabile e riutilizzabile in altri contesti.
Ma come li interroghiamo i dati?
Per farlo è necessario introdurre il linguaggio principe usato nel Web Semantico per le interrogazioni, cioè il linguaggio SPARQL.
Il linguaggio SPARQL è una raccomandazione W3C che definisce in modo standard come interrogare i dati, a partire da grafi RDF distribuiti nel Web. Il criterio di interrogazione è basato su un meccanismo di pattern matching, nello specifico dal costrutto triple pattern, che riflette il modello di asserzioni RDF delle triple e fornisce un modello flessibile per le ricerche.
Lo schema generico di un’interrogazione SPARQL è il seguente:
PREFIX ex: <http://example.org/>
SELECT ...
FROM ...
WHERE { ... }
ORDER BY ...
dove
-
PREFIX è la clausola che definisce prefissi e namespace, comoda per abbreviare le URI;
-
SELECT è la clausola che definisce le informazioni che vogliamo estrarre dal repository;
-
FROM è la clausola che definisce il grafo (o i grafi) da esplorare. Può essere sia locale sia remoto. Possiamo anche inserire clausole come FROM NAMED e GRAPH per specificare sorgenti dati multipli;
-
WHERE è la clausola che definisce il pattern del grafo che intendiamo cercare nel dataset; rappresenta la parte più importante della query;
-
ORDER BY è la clausola che mi consente di ordinare i risultati della ricerca.
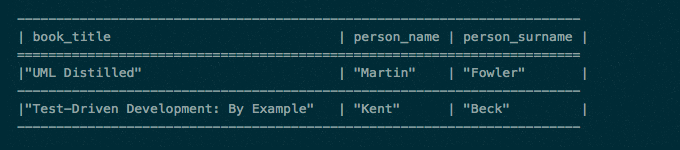
Immaginiamo di avere un dataset contenente un insieme di libri (risorse) descritti da una specifica ontologia nel file book.rdf, pubblicato nel Web secondo i principi dei Linked Data. Immaginiamo di identificare il dataset nel Web col seguente URL:
http://example.org/books.rdf .
Il nostro obiettivo è conoscere tutti i libri presenti del dataset con i relativi autori; per fare questo dobbiamo estrarre tutte le risorse di tipo libro (?book) e tutte le persone (?person) che sono autori (ex:hasAuthor) dei libri. Dei libri vogliamo conoscere i titoli (?book_title) e i nomi e cognomi degli autori (?person_name, ?person_surname).
La query di interrogazione sarà la seguente:
PREFIX ex: <http://example.org/>
SELECT ?book_title ?person_name ?person_surname
FROM <http://example.org/books.rdf>
WHERE { ?book a ex:Book;
ex:title ?book_title;
ex:hasAuthor ?person.
?person ex:name ?person_name;
ex:surname ?person_surname.
}
e questo un ipotetico risultato

Passiamo adesso ad OpenARS e proviamo ad effettuare un’interrogazione reale direttamente sul suo repository. A differenza del file pubblicato nell’esempio precedente i dati di OpenARS sono caricati su un server di storage dedicato che contiene l’intera base di conoscenza nella forma di triple/asserzioni . Per poter effettuare delle interrogazioni sui dati è necessario conoscere l’URL punto di ingresso, conosciuto con il nome di SPARQL endpoint.
E’ possibile effettuare l’interrogazione direttamente dal client Web fornito dal triple store, come nella figura sottostante oppure è possibile eseguire query SPARQL da codice sorgente di un qualsiasi linguaggio di programmazione se si vogliono sviluppare applicazioni che interagiscono con i dati.

Prima di effettuare qualsiasi tipo di ricerca è fondamentale conoscere l’ontologia di riferimento al fine di poter interrogare correttamente i dati per tipologie di classi e per connessioni esistenti tra le risorse.
Facciamo adesso qualche esempio di interrogazione relativa a statistiche sull’attività legislativa dell’ARS. Per esempio, vogliamo sapere quanti disegni di legge sono stati presentati nel corso della 16° legislatura.
La query SPARQL è la seguente:
PREFIX ars: <http://www.openars.org/core#>
SELECT count(?ddl)
FROM <http://www.openars.org/9/>
WHERE {
?ddl a ars:DisegnoDiLegge;
ars:legislatura <http://dati.openars.org/legislatura/xvi>
}
che restituirà come risultato il valore 1346. Provare per credere.
La query assomiglia molto al linguaggio SQL e risulta di per sé molto leggibile. Nel campo WHERE selezioniamo tutte le risorse dello store di tipo ars:DisegnoDiLegge che sono collegate, tramite la proprietà ars:legislatura, alla risorsa che identifica la sedicesima legislatura (http://dati.openars.org/legislatura/xvi ).
La selezione restituisce un certo numero di istanze e nel campo SELECT decidiamo di calcolare il numero totale di tali istanze, tramite l’operatore di aggregazione count, che corrisponde al numero totale di disegni di legge della 16° legislatura.
Vediamo adesso qualcosa un pò più complesso.
Voglio sapere la classifica top ten dei disegni di legge presentati nella 16° legislatura suddivisa per materia.
La query SPARQL è la seguente:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX ars: <http://www.openars.org/core#>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT ?nomeMateria count(?ddl) as ?num
FROM <http://www.openars.org/9/>
WHERE {
?topic a ars:Materia.
?ddl a ars:DisegnoDiLegge;
ars:materia ?topic;
ars:legislatura <http://dati.openars.org/legislatura/xvi>.
?topic ars:nomeMateria ?nomeMateria.
}
GROUP BY ?nomeMateria
ORDER BY DESC(?num)
LIMIT 10
Questo il risultato:

Alcune considerazioni finali:
-
questi sono solo piccoli esempi che si possono fare con i dati ARS, nel prossimo post presenteremo casi molto più complessi che prenderanno in considerazione interrogazioni a sorgenti dati multipli;
-
passando dal Web di documenti al Web di dati (linked-data), il Web diventa machine-understandable e il tutto risulta esponenzialmente vantaggioso in termini di flessibilità e di interoperabilità semantica;
-
con la pubblicazione dei dati in modalità linked il Web diventa data-centric e le possibili interrogazioni dei dati, grazie alle loro interconnessioni, sia dentro che fuori al dataset, diventano pressoché infinite e delle più disparate;
-
non ci credete? provate a reperire nel Web tradizionale i nomi di TUTTI i sindaci le cui città hanno lo stesso patrono della città collegio di elezione di un qualsiasi deputato dell’ARS
Nel prossimo post vedremo quanto sarà facile farlo con OpenARS.
Alcuni link per approfondire il linguaggio SPARQL
- SPARQL By Example – A Tutorial
- Learning SPARQL
- Using SPARQL to access Linked Open Data
- Your First SPARQL Query
p.s. le iscrizioni al raduno sono ancora aperte. I posti sono gratuiti ma limitati. Per maggiori informazioni questo è il sito dell’evento.
Alla prossima